우분투 20.04에서 typesense 서버 설치부터 node.js 클라이언트 예제 실행까지
들어가며
얼마 전 geeknews에 등록된 2백만개 음식 레시피 검색 엔진 게시글을 읽어본 뒤, 이 엔진의 검색 속도가 정말 빠르기에 한번 사용해보고싶다는 생각이 들어서 간단하게 서버에 설치 후 클라이언트를 사용 해 보았습니다. 현재의 게시글에서는 웹애플리케이션을 통해 검색결과를 표현하는 형태가 아닌, 공식 가이드 문서에서 설명하고 있는 방법을 한글 샘플 데이터로 간단히 사용하는 방법을 알아보려고 합니다. 실제로 한번 설치 후 사용 해 보니 그리 어렵지 않게 사용할 수 있을 것 같아서, 정리할 겸 이렇게 게시글을 작성하게 되었습니다.
사전 준비
필수
- Ubuntu 운영체제 (아래 모든 코드는 우분투 20.04 기준으로 테스트 되었습니다.)
- root 또는 sudo 명령을 사용할 수 있는 권한을 가진 사용자로 서버에 SSH 접속이 가능해야 함
선택
- node.js v14.x 사전 설치 (현재 설치되어있지 않은 경우 아래 과정을 통해 설치 가능)
Typesense 및 Node.js v14.x 설치
Ubuntu용 pre-built 바이너리 다운로드
# 현재 기준 최신버전 0.17.0
wget --trust-server-names https://dl.typesense.org/releases/0.17.0/typesense-server-0.17.0-amd64.deb
바이너리 설치
# 설치 성공 후 자동으로 typesense-server가 실행됨
sudo apt install ./typesense-server-0.17.0-amd64.deb
기본 설정 파일 확인
; /etc/typesense/typesense-server.ini
; Typesense Configuration
[server]
api-address = 0.0.0.0
api-port = 8108
data-dir = /var/lib/typesense
api-key = 자동으로생성된마스터API키
log-dir = /var/log/typesense
서버 실행상태 확인
curl http://localhost:8108/health
# 기대 응답> {"ok":true}
node.js v14.x 설치
- 이미 설치되어 있는 경우 생략 가능
- 설치 참고 문서
curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash -
sudo apt-get install -y nodejs
Typesense client 설치
같은 서버의 ~/typesense-client 디렉토리에 실습을 위한 node.js용 패키지 설치
mkdir ~/typesense-client
cd ~/typesense-client
npm install typesense @babel/runtime public-google-sheets-parser
예제 코드 실습
node REPL 실행
- node v14.x에서 await를 async 함수 본문이 아니어도 사용할 수 있도록 하는
--experimental-repl-await옵션을 준 뒤 REPL을 실행합니다.
node --experimental-repl-await
실습에 필요한 패키지 선언 및 클라이언트 객체 생성
# 아래의 순서대로 쭉 작성 해 봅니다.(공식 문서에 나와있는 내용 거의 그대로 진행)
# apiKey는 /etc/typesense/typesense-server.ini 파일에 입력된 내용을 미리 확인하여 준비 해 주세요.
const Typesense = require('typesense')
const PublicGoogleSheetsParser = require('public-google-sheets-parser')
const parser = new PublicGoogleSheetsParser()
const client = new Typesense.Client({
nodes: [{
host: 'localhost',
port: '8108',
protocol: 'http'
}],
apiKey: '/etc/typesense/typesense-server.ini에 기록된 키',
connectionTimeoutSeconds: 2
})
books 컬렉션 생성 후 결과 확인
- 컬렉션은 관계형 데이터베이스에서의 Table과 거의 같은 개념(roughly equivalent to a table in a relational database)입니다. 도큐먼트는 Table의 한 row를 의미한다고 생각하시면 될 것 같습니다.
const booksSchema = {
name: 'books',
fields: [
{ name: 'title', type: 'string' },
{ name: 'authors', type: 'string[]' },
{ name: 'publisher', type: 'string' },
{ name: 'publication_year', type: 'int32' },
{ name: 'ratings_count', type: 'int32' },
{ name: 'average_rating', type: 'float' },
{ name: 'authors_facet', 'type': 'string[]', 'facet': true },
{ name: 'publication_year_facet', 'type': 'string', 'facet': true },
],
default_sorting_field: 'ratings_count',
}
const afterCreateBooksSchema = await client.collections().create(booksSchema)
// 궁금하시다면 afterCreateBooksSchema를 확인 해 보세요. 여기서는 부연설명을 하지 않겠습니다.
books 컬렉션에 도서 등록
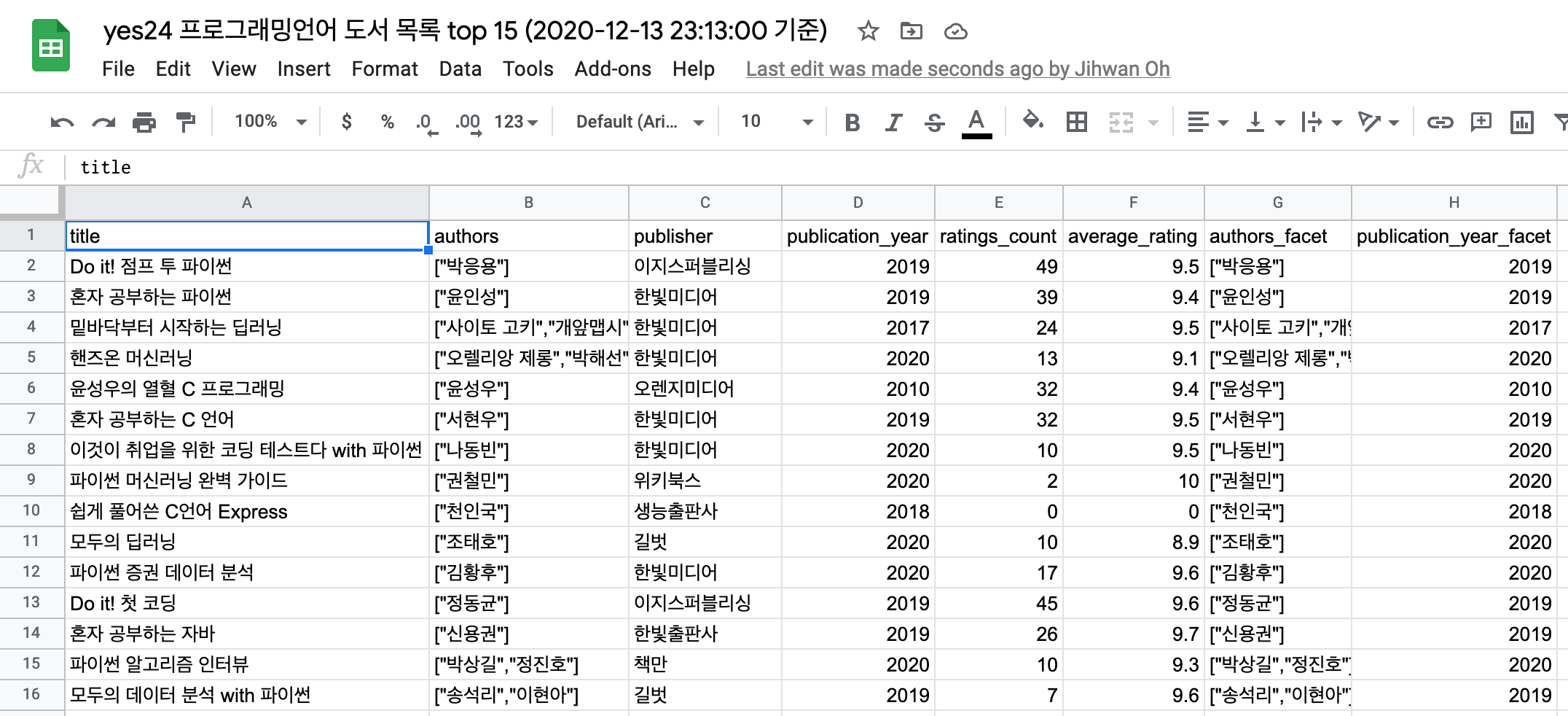
- public-google-sheets-parser를 이용해 이미 만들어 둔 샘플 도서 정보를 받아서, books 컬렉션의 document로 등록합니다.
- 16i6SZEmwZ_F1MO2pGNJeq7WLJ6bP0QJkXKA_vA0GTG8
const booksSpreadsheetId = '16i6SZEmwZ_F1MO2pGNJeq7WLJ6bP0QJkXKA_vA0GTG8'
const rawBooks = await parser.parse(booksSpreadsheetId)
const books = rawBooks.map((book) => {
// 각각 올바른 타입으로 형변환 합니다.
book.authors = JSON.parse(book.authors)
book.authors_facet = JSON.parse(book.authors_facet)
book.publication_year_facet = `${book.publication_year_facet}`
return book
})
// 얻어온 book 정보를 books 컬렉션에 document로 각각 추가합니다.
books.forEach((book) => client.collections('books').documents().create(book))
books 검색
제목에 파이썬이 들어간 도서 찾기
- q, query_by, sort_by 속성을 이용하여 document를 검색합니다. sort_by 속성의 콜론을 확인 해 보시면 내림차순 정렬을 간단하게 할 수 있음을 확인할 수 있습니다.
// 아래 실행할 코드에서 재활용하기 위해 let으로 선언합니다. (이하 마찬가지)
let searchParameters = {
q: '파이썬',
query_by: 'title',
sort_by: 'ratings_count:desc'
}
let searchResults = await client.collections('books').documents().search(searchParameters)
/** 결과는 다음과 같습니다.
{
facet_counts: [],
found: 7, // 파이썬이라는 키워드가 들어간 책이 15권 중에 7권 이라니.. 엄청난 인기군요 ^^;
hits: [
{
document: {
authors: [ '박응용' ],
authors_facet: [ '박응용' ],
average_rating: 9.5,
id: '0',
publication_year: 2019,
publication_year_facet: '2019',
publisher: '이지스퍼블리싱',
ratings_count: 49,
title: 'Do it! 점프 투 파이썬'
},
highlights: [
{
field: 'title',
matched_tokens: [ '파이썬' ],
snippet: 'Do it! 점프 투 파이썬'
}
],
text_match: 33488996
},
// ... 생략
],
page: 1,
request_params: { per_page: 10, q: '파이썬' },
search_time_ms: 0
}
*/
- 편의상 hits의 첫 번째 아이템만 펼쳐 보았습니다. hit된 document는 원본 정보를, highlights에는 대상 필드에 일치된 키워드에
mark태그가 붙은 결과를 snippet 속성에 담아 내려줍니다.
평점이 9.6 이상인 파이썬 도서만 검색하기
- filter_by 조건을 통해 원하는 조건을 만족하는 도큐먼트만 추릴 수 있습니다. 만약 여러 조건으로 필터링 해야한다면
&&연산자를 사용하여 추가 조건을 계속 나열할 수 있습니다.
searchParameters = {
q: '파이썬',
query_by: 'title',
filter_by: 'average_rating:>9.6',
sort_by: 'average_rating:desc'
}
searchResults = await client.collections('books').documents().search(searchParameters)
/** 결과는 다음과 같습니다.
{
facet_counts: [],
found: 1,
hits: [
{
document: {
authors: [ '권철민' ],
authors_facet: [ '권철민' ],
average_rating: 10,
id: '7',
publication_year: 2020,
publication_year_facet: '2020',
publisher: '위키북스',
ratings_count: 2,
title: '파이썬 머신러닝 완벽 가이드'
},
highlights: [
{
field: 'title',
matched_tokens: [Array],
snippet: '파이썬 머신러닝 완벽 가이드'
}
],
text_match: 33488996
}
],
page: 1,
request_params: { per_page: 10, q: '파이썬' },
search_time_ms: 0
}
*/
마치며
공식 가이드 문서에는 패싯 검색 등 다른 예제가 더 있지만, 제가 이 부분을 위한 데이터를 만들기가 귀찮(-_-;)아서 일단은 여기까지만 간단하게 사용 방법을 확인 해 보았습니다. 관심이 있으시다면 해당 문서를 확인 해 보세요!
고가용성(High Availability)을 위한 설정도 매우 간단하고, 검색 속도도 굉장히 빠르기 때문에 검색서버를 운영할 계획이 있으시다면 관심가지고 한번 확인 해 보시는것이 좋을 것 같습니다. 단, GPLv3 라이센스이기때문에 이 부분은 확실히 확인 후 결정하시면 될 것 같습니다. (검색용 API 서버로 분리해 두면 별 이슈는 없는 것으로 알고 있습니다.)
충분히 많은 데이터셋을 통해 웹 브라우저에서 검색 속도 테스트를 해 보고 싶은데, 이 부분은 다음에 데모용 데이터셋을 많이 만들어낸 뒤, 데모 웹사이트를 만들어 다른 게시글을 통해 소개할 수 있도록 해 볼 계획입니다.
읽어주셔서 감사합니다~